Кто такой data scientist, чем он занимается и сколько зарабатывает
Учёный без учёной степени, но с хорошей зарплатой!


Данных в мире становится всё больше: по оценкам аналитиков, за 2025 год человечество накопило около 181 зеттабайта информации — это триллионы гигабайт, и объём продолжает расти с каждым годом. Однако сами по себе данные не приносят пользы. Ценность появляется тогда, когда их анализируют и используют для принятия решений. Именно этим занимается data science — область на стыке статистики, программирования и машинного обучения, которая помогает превращать сырые данные в полезные выводы.
Когда маркетплейс рекомендует товары, которые могут вас заинтересовать, банк оценивает кредитные риски, а стриминговый сервис подбирает музыку под ваши предпочтения, за этим часто стоит работа специалистов по данным. Один из них — дата-сайентист.
В этой статье разберём, кто такой data scientist, чем он занимается, какими навыками владеет и сколько зарабатывает.
Содержание
- Что такое data science и кто такой data scientist
- Чем занимается специалист по данным
- В каких сферах он работает
- Что должен знать и уметь дата-сайентист
- Сколько зарабатывает data scientist в 2026 году
- Как стать дата-сайентистом с нуля
- Плюсы и минусы профессии
- Коротко о главном
Что такое data science и кто такой дата-сайентист
Дата-сайенс (data science, наука о данных) — это дисциплина на стыке трёх областей: программирования, математики и понимания бизнеса. Её главная задача — извлечь из имеющихся данных полезную информацию, на которую можно опереться при принятии решений.
Дата-сайентист (data scientist) — это специалист, который решает такие задачи с помощью машинного обучения. Он создаёт алгоритмы, способные находить в данных неочевидные закономерности, и на их основе делать прогнозы.
Результаты работы специалистов по анализу данных окружают нас повсюду, хотя мы редко это замечаем. Например, алгоритмы советуют, какой фильм посмотреть вечером, разблокируют смартфон по лицу, за доли секунды одобряют или отклоняют заявку на кредит и так далее.
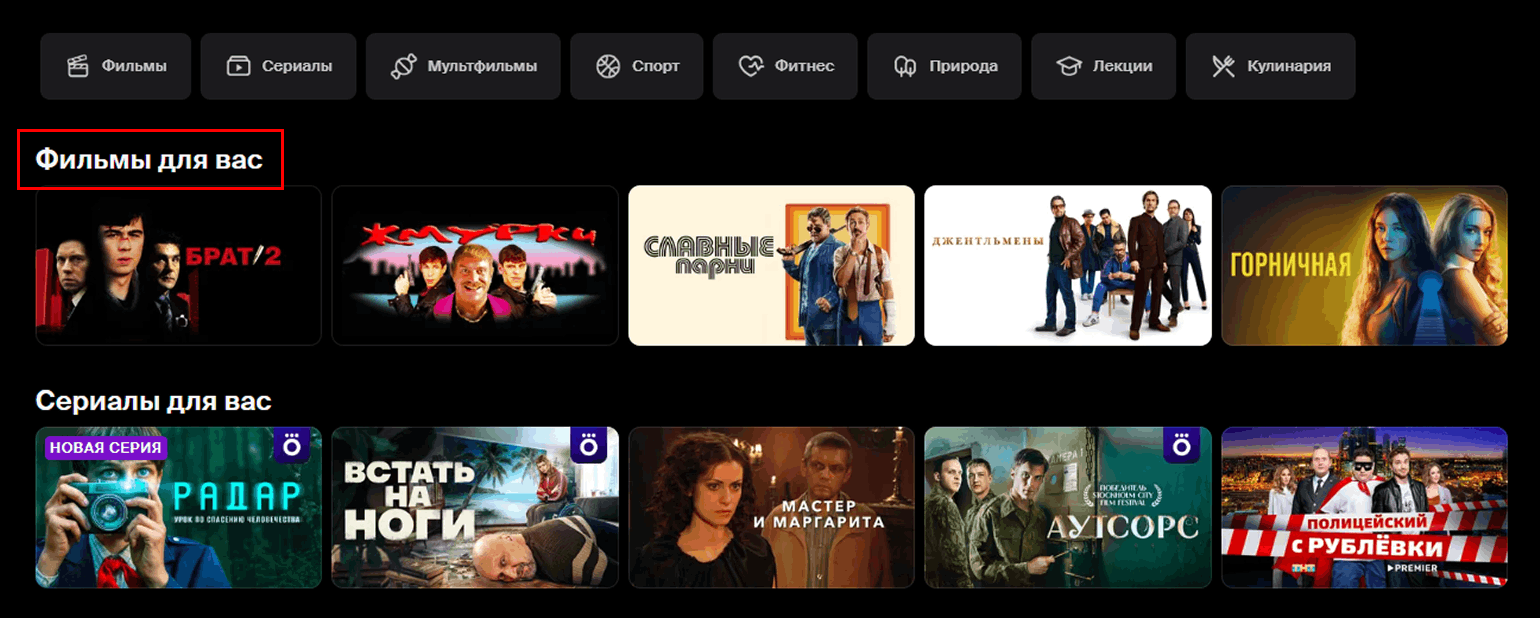
Скриншот: Okko / Skillbox Media
Профессия дата-сайентиста пережила бум в 2010-х: вычислительные мощности выросли, а данных накопилось столько, что обрабатывать их вручную стало невозможно. Символическим маркером бума стал 2012 год: Harvard Business Review назвал профессию дата-сайентиста «самой сексуальной работой XXI века».
В 2020-х профессию меняет генеративный искусственный интеллект. Многие задачи, которые раньше выполнялись вручную — написание кода, подготовка запросов, очистка данных и первичный анализ, — теперь частично автоматизируются. Поэтому роль дата-сайентиста постепенно смещается от технической рутины к проектированию моделей, оценке их качества и решению бизнес-задач.
Чем занимается data scientist
Будет ошибкой думать, что дата-сайентист целыми днями обучает нейросети. Его главная задача — решать бизнес-задачи с помощью данных, а модели машинного обучения — лишь один из инструментов для этого.
Рабочие задачи дата-сайентиста
Типичный рабочий процесс специалиста включает несколько этапов:
- Постановка задачи. Data scientist общается с заказчиками (менеджерами, маркетологами, продуктовыми командами) и переводит бизнес-запрос в задачу, которую можно решить с помощью данных. Например, определить вероятность оттока клиентов или спрогнозировать спрос на товар.
- Сбор и подготовка данных. Специалист получает данные из корпоративных хранилищ и баз данных — чаще всего с помощью SQL-запросов — и объединяет их для дальнейшего анализа.
- Очистка данных. На этом этапе он удаляет дубликаты, исправляет ошибки, обрабатывает пропущенные значения и аномалии. Качество данных напрямую влияет на качество будущей модели.
- Разработка признаков (feature engineering). Data scientist создаёт новые переменные, которые помогают алгоритму находить закономерности. Например, рассчитывает средний чек клиента или частоту покупок за определённый период.
- Построение и обучение моделей. После подготовки данных специалист выбирает подходящий алгоритм, обучает модель и оценивает качество её работы.
- Презентация результатов. Полученные выводы нужно объяснить команде и показать, какую пользу они принесут бизнесу. Даже самая точная модель ничего не стоит, если её нельзя внедрить в рабочие процессы.
Конкретный набор задач зависит от компании, проекта и уровня специалиста. Чем выше грейд, тем больше ответственности за выбор решений и влияние на бизнес-результат.
Как это выглядит на практике
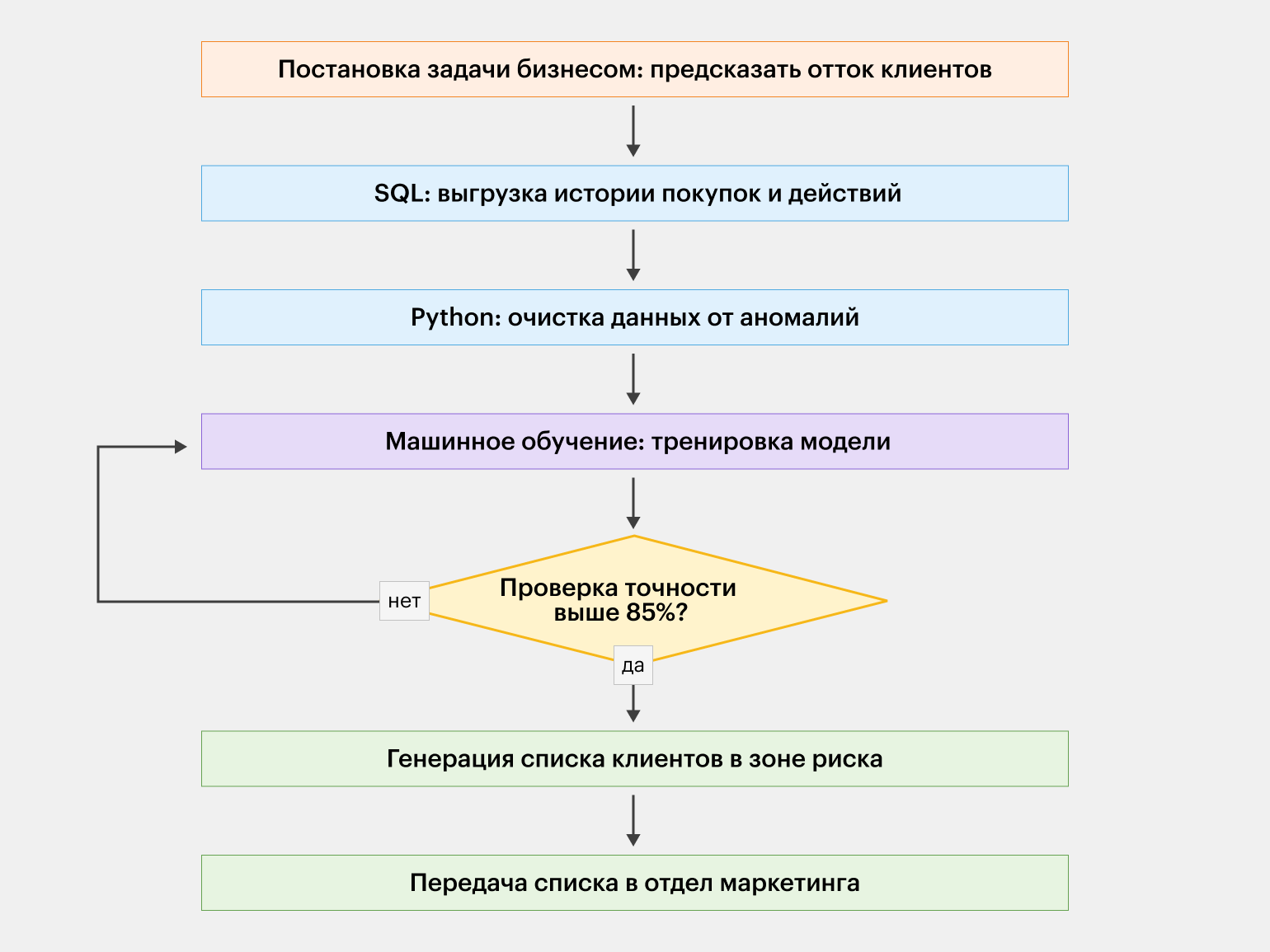
Чтобы лучше понять профессию, рассмотрим пример из практики. Представьте, что вы работаете дата-сайентистом в крупном интернет-магазине.
Компания заметила, что часть клиентов перестала возвращаться за повторными покупками. Маркетинговая команда ставит задачу: научиться заранее определять пользователей с высоким риском оттока, чтобы вовремя предложить им скидку или персональное предложение.
В такой ситуации data scientist может действовать так:
- Изучить задачу. Вместе с маркетологами определить, что считается оттоком, какие клиенты наиболее ценны для бизнеса и как будут использоваться результаты модели.
- Собрать данные. Получить информацию о покупках клиентов, активности на сайте, возвратах товаров и обращениях в поддержку — обо всех факторах, которые могут быть связаны с оттоком.
- Подготовить данные. Удалить ошибки, обработать пропущенные значения, исправить аномалии и привести данные к формату, пригодному для анализа.
- Построить модель. Выбрать алгоритм машинного обучения и обучить его на исторических данных, чтобы он находил закономерности в поведении клиентов.
- Оценить качество модели. Проверить, насколько хорошо она определяет пользователей с высоким риском оттока на новых данных.
- Передать результаты бизнесу. Сформировать список клиентов с повышенной вероятностью ухода и передать его маркетинговой команде для запуска удерживающей кампании.
Если модель работает достаточно хорошо, компания может заранее реагировать на риск оттока, удерживать больше клиентов и снижать потери выручки. Именно такие задачи и решают дата-сайентисты в бизнесе.
Изображение: Skillbox Media
В каких сферах работают дата-сайентисты
Сегодня данные собирают практически все крупные организации — от банков и маркетплейсов до производственных предприятий и медицинских центров. Поэтому дата-сайентисты востребованы во многих отраслях и не ограничены только IT-компаниями. Разберём основные сферы.
Банки и финтех. Модели машинного обучения помогают оценивать кредитные риски, выявлять мошеннические операции, прогнозировать поведение клиентов и автоматизировать финансовые решения. Например, алгоритмы анализируют данные заёмщика при рассмотрении заявки на кредит или находят нетипичные транзакции, похожие на мошенничество.
Ретейл и e-commerce. В торговле data science используют для прогнозирования спроса, управления запасами и персонализации рекомендаций. Алгоритмы помогают планировать поставки, прогнозировать продажи и предлагать покупателям наиболее релевантные товары.
Медицина и HealthTech. Специалисты по данным участвуют в анализе медицинских изображений, разработке диагностических систем и исследованиях новых лекарств. Например, нейросети распознают опухоли на МРТ и рентгеновских снимках — иногда точнее, чем замечает глаз уставшего за смену врача, — а при разработке препаратов предсказывают, как молекулы будут взаимодействовать друг с другом, отсекая неудачные варианты до дорогих испытаний.
Промышленность и логистика. На производстве data scientist помогает предотвращать поломки и простои, обрабатывая данные с оборудования. Например, на заводах датчики непрерывно собирают информацию о вибрации и температуре станков, а модели предиктивного обслуживания предсказывают, когда деталь вот-вот сломается, — чтобы заменить её заранее, до аварии и остановки конвейера.
Телеком. Операторы связи применяют машинное обучение для прогнозирования оттока клиентов, персонализации тарифов, анализа качества связи и планирования нагрузки на сеть.
Во всех этих сферах задачи могут различаться, но цель остаётся одной — извлекать из данных информацию, которая помогает бизнесу принимать более точные решения.
Что должен знать и уметь дата-сайентист
Требования к специалистам меняются от компании к компании и от проекта к проекту, но база остаётся одной. Работодатели ждут двух вещей: уверенного владения инструментами для работы с данными и понимания математики, которая стоит за алгоритмами. Разберём, что входит в этот фундамент.
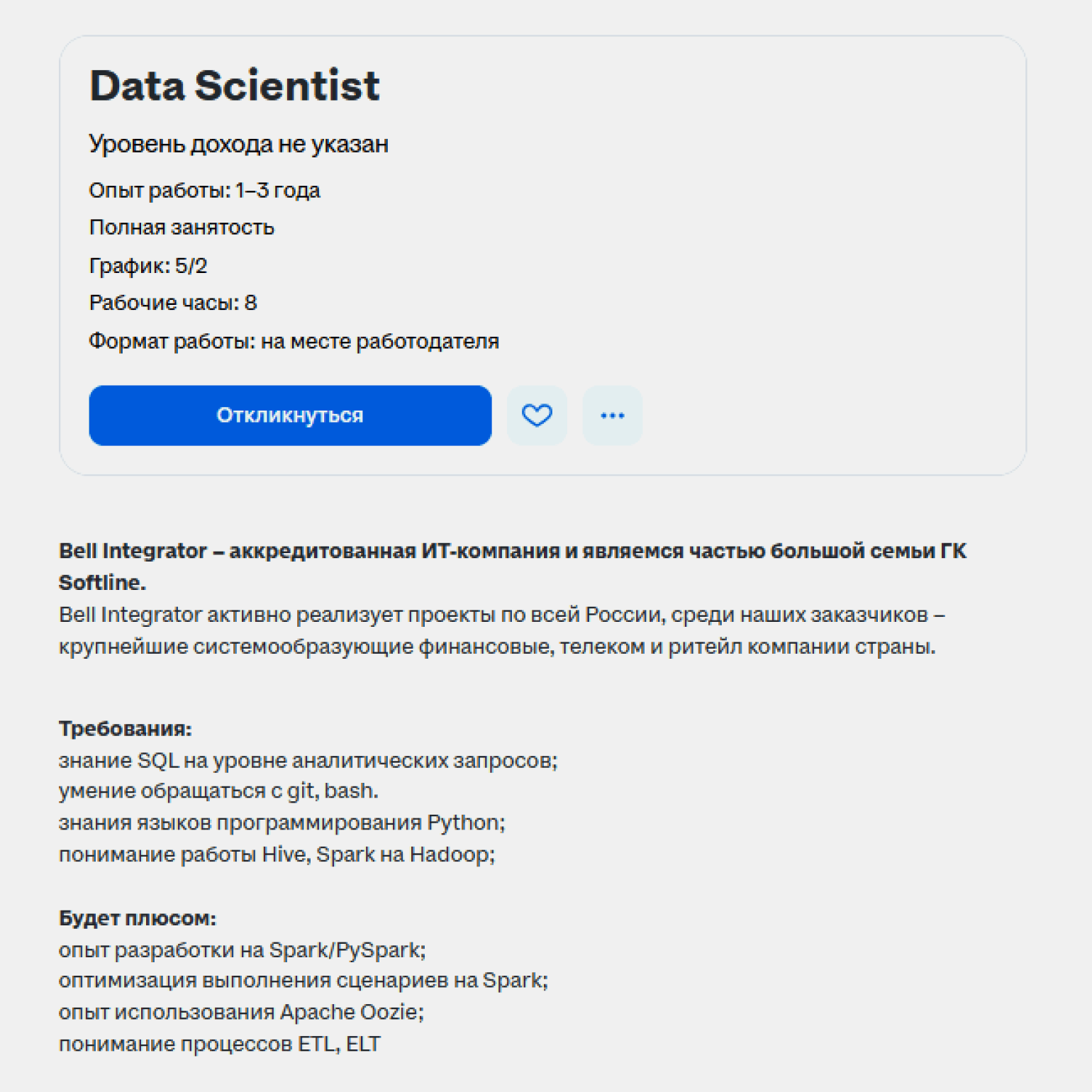
Скриншот: hh.ru / Skillbox Media
Python. Основной язык в data science. Специалисты выбирают его за простой синтаксис и огромное количество готовых библиотек для машинного обучения и анализа данных: многое не нужно писать с нуля, достаточно подключить готовый инструмент. На старте хватит трёх библиотек.
- Pandas — главный инструмент для работы с табличными данными. Позволяет загружать таблицы, очищать и фильтровать их, заполнять пропуски и объединять разные наборы данных. По сути, это Excel на стероидах, которым управляют кодом.
- NumPy — библиотека для быстрых математических вычислений. Эффективно работает с многомерными массивами и матрицами, на которых строится большинство алгоритмов машинного обучения.
- Scikit-learn — базовый набор инструментов для классического машинного обучения. Содержит готовые модели регрессии, классификации и кластеризации, которые можно обучить буквально в несколько строк кода.
SQL. Язык запросов к базам данных. Почти вся информация в компаниях хранится в таблицах, поэтому data scientist должен уметь быстро доставать нужные строки, объединять таблицы между собой и фильтровать данные. Без SQL вы попросту не доберётесь до материала, с которым предстоит работать.

Математика и статистика. Понять, как работают алгоритмы, невозможно без линейной алгебры, теории вероятностей и математического анализа. Решать уравнения на бумаге дата-сайентисту не придётся, но смысл формул, зашитых в код, он понимать должен — иначе будет применять модели вслепую, не зная, как они работают и почему ошибаются.
Машинное обучение. Одна из главных целей работы с данными — обучать на них модели и нейросети. Поэтому data scientist должен понимать, как устроены методы обучения: градиентный спуск, линейная и логистическая регрессии и так далее.
Реализацией и тонкой оптимизацией алгоритмов часто занимаются смежные специалисты — ML-инженеры. Но здесь есть два «но». Во-первых, не в каждой компании есть отдельные ставки и для дата-сайентиста, и для ML-инженера — нередко всё это делает один человек. Во-вторых, именно data scientist решает, какие признаки в итоге должна распознавать модель, — а это половина успеха.
Инфраструктура и инструменты разработки (Git, Bash). Дата-сайентисты редко работают в одиночку. Для совместной разработки и управления изменениями в коде используют Git.
Bash и командная строка помогают работать с Linux-серверами, на которых обычно выполняются вычисления, обработка данных и обучение моделей машинного обучения.
Технологии Big Data (Hadoop, Hive, Spark). Когда объём данных становится слишком большим для обработки на одном компьютере, используют распределённые вычисления: задачи и данные распределяются между несколькими серверами. Поэтому дата-сайентисту полезно понимать принципы работы с Big Data и базово владеть популярными инструментами:
- Hadoop — платформа для хранения и распределённой обработки больших объёмов данных;
- Hive — инструмент, который позволяет работать с данными в Hadoop с помощью SQL-подобных запросов;
- Spark — фреймворк для быстрой обработки данных и выполнения аналитических задач на кластерах серверов.
На практике дата-сайентисты не всегда настраивают такие системы самостоятельно, но понимание их устройства помогает эффективнее работать с большими объёмами данных и взаимодействовать с дата-инженерами.
ETL и ELT. Это подходы к организации потоков данных между разными системами. Аббревиатуры расшифровываются как Extract, Transform, Load — «извлечение, преобразование и загрузка». Разница между ETL и ELT заключается в том, на каком этапе выполняется обработка данных: до загрузки в хранилище или после неё.
Дата-сайентисту полезно понимать, как данные попадают из исходных систем в аналитические хранилища и отчёты. Для автоматизации таких процессов используют инструменты оркестрации, например Apache Airflow. Они позволяют запускать задачи по расписанию и поддерживать данные в актуальном состоянии без ручного вмешательства.
Если вы хотите освоить навыки дата-сайентиста с нуля, у Skillbox есть курс «Data Scientist с нуля до Junior». Обучение построено вокруг практики: вы работаете с реальными наборами данных под руководством наставников, разбираете код с менторами и к концу курса собираете портфолио из готовых проектов.
Сколько зарабатывает data scientist в 2026 году
Data scientist остаётся одной из самых высокооплачиваемых профессий в IT. Согласно опросу Stack Overflow за 2025 год, специалисты по data science в среднем зарабатывают 83 тысячи долларов, опережая по уровню зарплат разработчиков.

Скриншот: Stack Overflow / Skillbox Media
По данным «Хабр Карьеры» за второе полугодие 2025 года, медианная зарплата data scientist в России — 240 000 рублей.
На заработную плату заметно влияет грейд специалиста:
- junior (опыт до полутора лет) — около 136 тысяч рублей;
- middle (опыт 2–4 года) — около 248 тысяч рублей;
- senior (опыт от четырёх лет) — около 391 тысячи рублей.
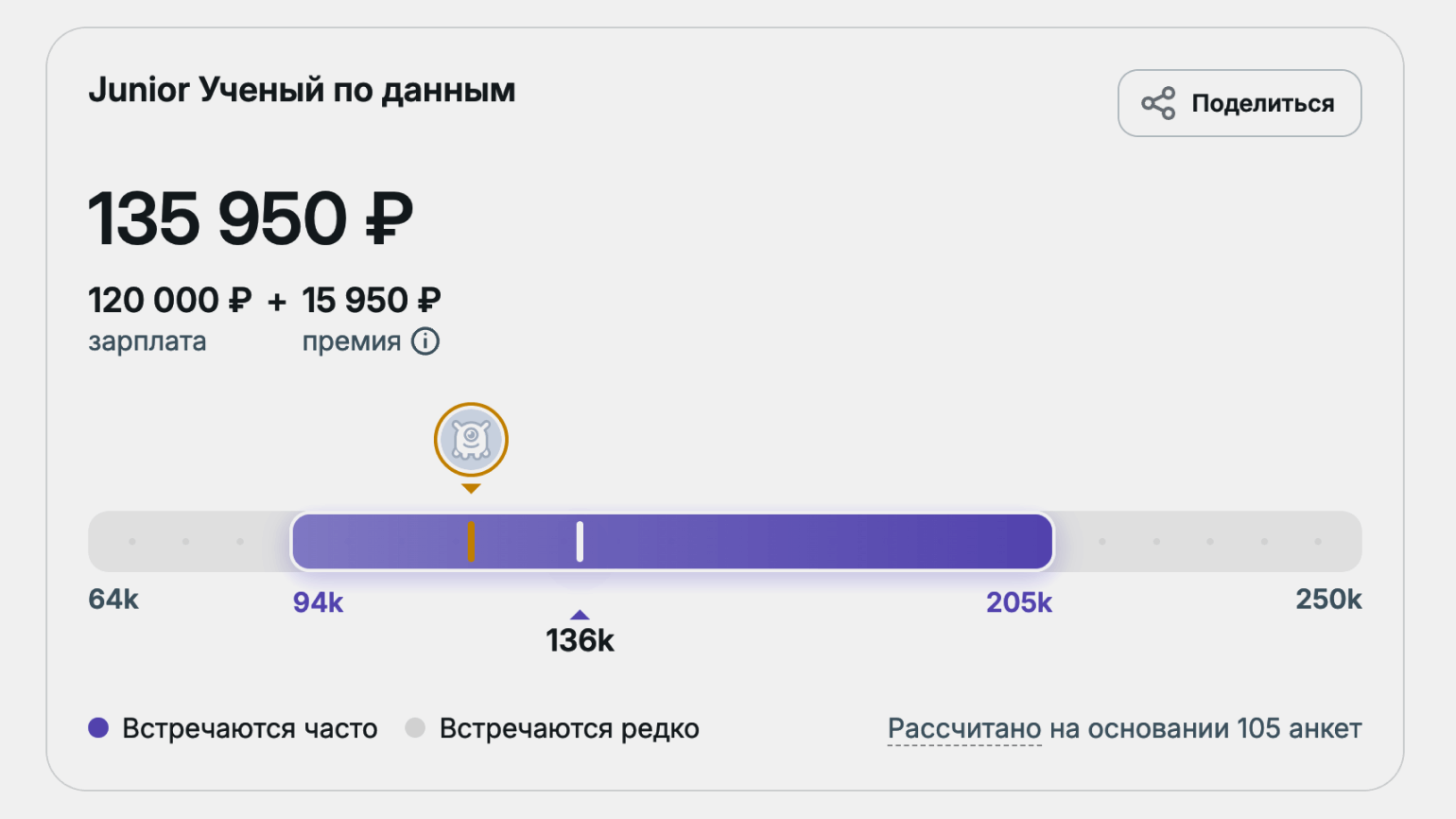
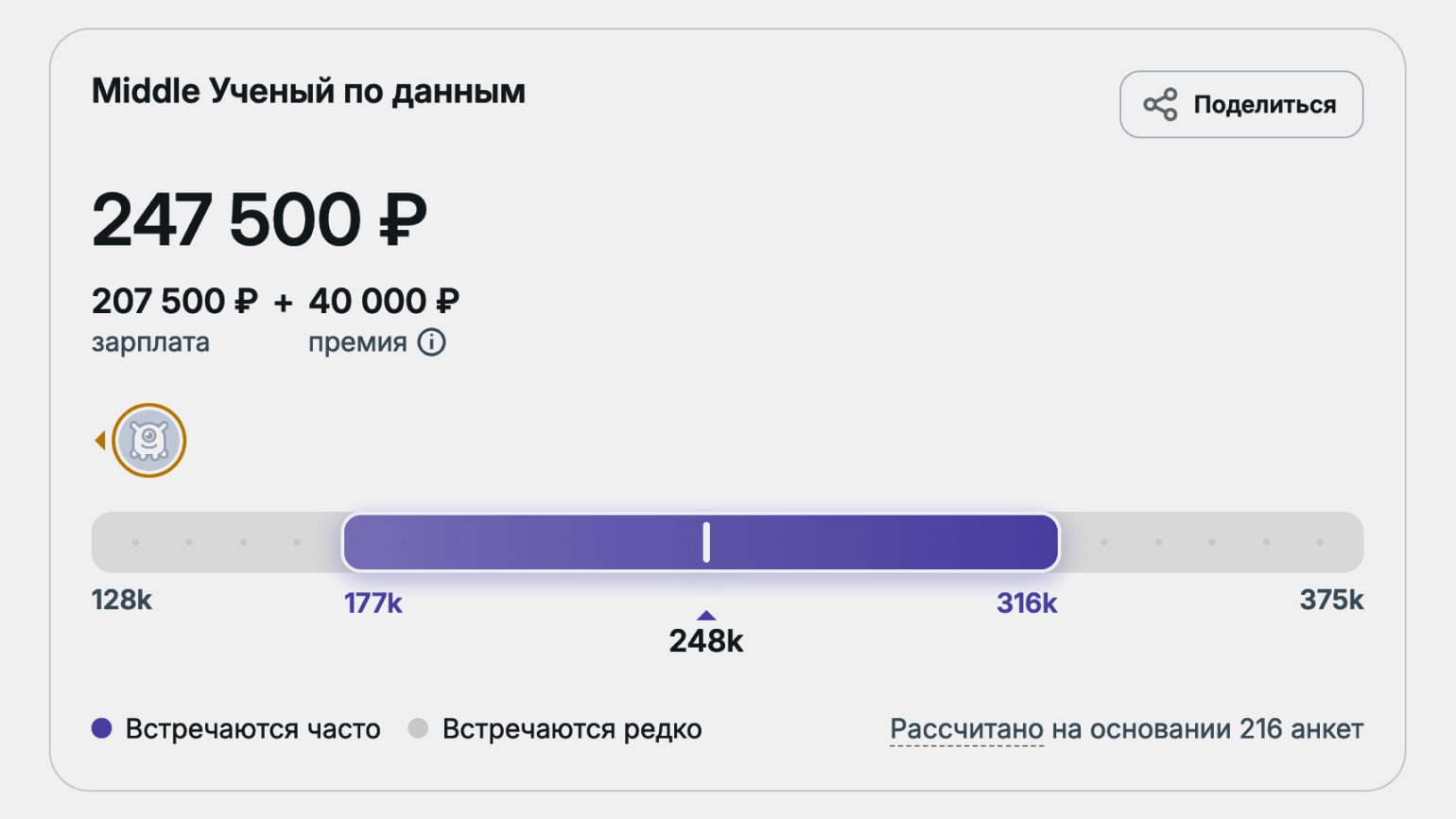
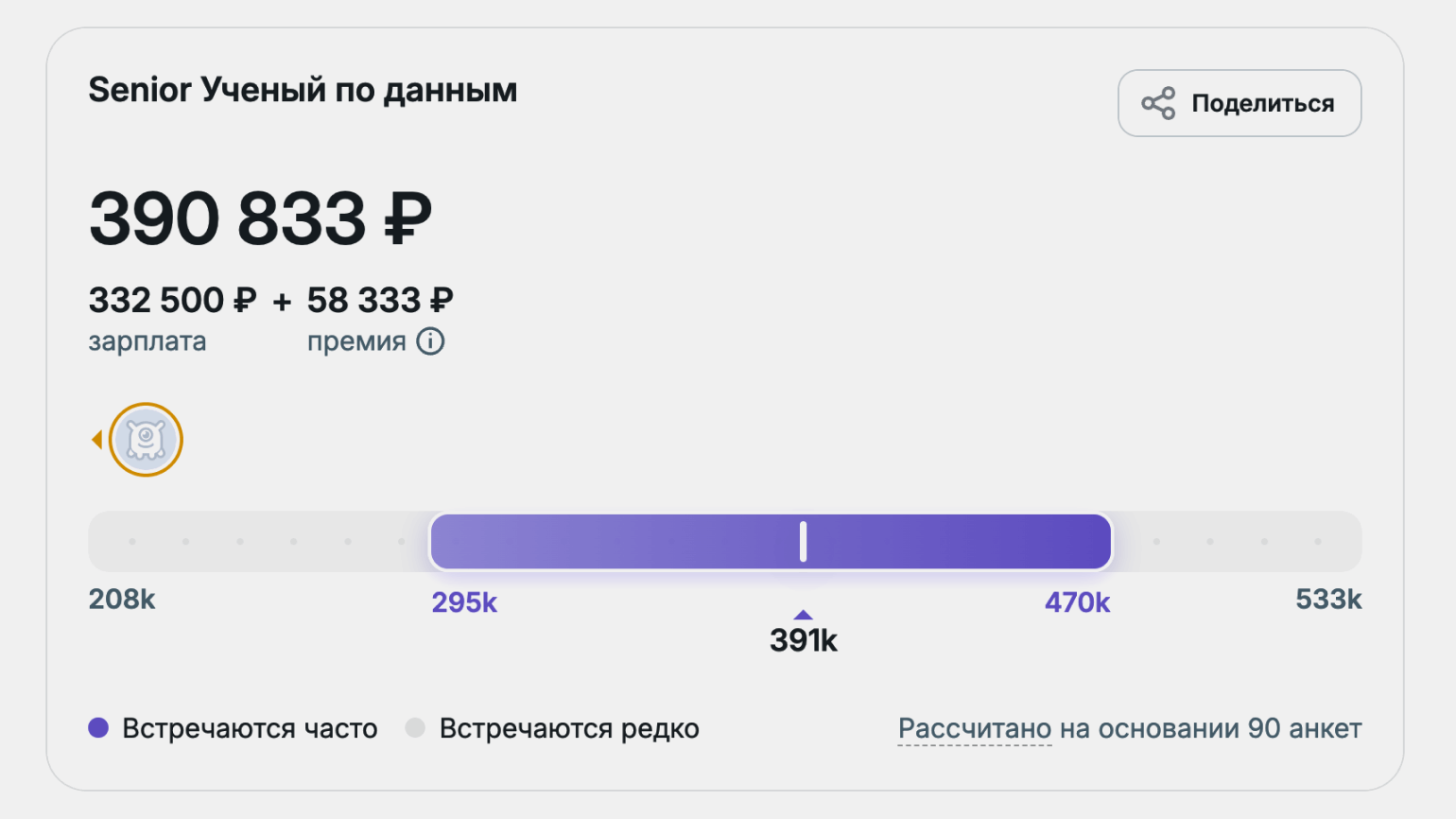
На международном рынке уровень зарплат выше. Например, в США специалисты по анализу данных зарабатывают в среднем около 156 тысяч долларов в год. В крупных технологических компаниях и стартапах доход может доходить до 300 тысяч долларов в год и выше.

Как стать data scientist с нуля
Войти в data science можно и без профильного образования. Однако для трудоустройства недостаточно изучить теорию. Нужно научиться работать с реальными данными, строить и проверять модели, анализировать ошибки и понимать причины снижения качества прогнозов.
Разберём, как пошагово стать дата-сайентистом.
Шаг 1: изучите требования к стажёрам и junior-специалистам
Прежде чем составлять план обучения, изучите требования работодателей. Для этого достаточно открыть несколько вакансий стажёров и junior data scientist на hh.ru и посмотреть, какие навыки чаще всего встречаются в описании.
Хотя требования могут различаться в зависимости от компании и команды, базовый набор компетенций обычно выглядит так:
- математика и статистика — знание теории вероятностей, математической статистики и методов проверки гипотез;
- программирование — уверенное владение Python и основными библиотеками для анализа данных;
- базы данных — умение писать SQL-запросы и работать с данными из реляционных СУБД;
- машинное обучение — понимание основных алгоритмов и принципов построения моделей.

Скриншот: hh.ru / Skillbox Media
Шаг 2: разберитесь в математике и статистике
Математика и статистика — основа data science. Без них модели машинного обучения превращаются в набор непонятных формул и настроек, которые приходится использовать вслепую.
Глубоко погружаться в высшую математику на старте не обязательно. Для первых проектов достаточно понимать основные статистические концепции: среднее и медиану, распределения данных, дисперсию, корреляцию, доверительные интервалы, p-value и проверку гипотез. Эти знания помогут анализировать данные, оценивать качество моделей и понимать, насколько надёжны полученные результаты.
Где учить: бесплатный курс «Основы статистики» Анатолия Карпова на Stepik. Видеоуроки и задания помогут разобраться в базовых понятиях статистики без глубокого погружения в математику.
Для дальнейшего изучения машинного обучения также пригодятся основы линейной алгебры и теории вероятностей, но осваивать их лучше постепенно, параллельно с практикой. Это поможет быстрее увидеть связь между математикой и реальными задачами data science.
Шаг 3: освойте Python и SQL
Python и SQL — основные инструменты дата-сайентиста. Python используют для обработки данных, анализа, визуализации и обучения моделей машинного обучения. SQL нужен для работы с базами данных: с его помощью специалисты получают нужные данные, объединяют таблицы и готовят информацию для дальнейшего анализа.
Где учить: начать изучение Python можно с бесплатного курса «„Поколение Python“: курс для начинающих» на Stepik. Для освоения SQL подойдёт интерактивный тренажёр SQL Academy, где можно на практике разобраться с запросами, фильтрацией данных, объединением таблиц и группировкой результатов.
Параллельно стоит освоить среду для работы с данными. Чаще всего дата-сайентисты используют Jupyter Notebook или облачный сервис Google Colab. В них удобно писать код, анализировать данные, строить графики и запускать модели машинного обучения в одном рабочем пространстве.

Шаг 4: разберитесь в алгоритмах и моделях
После того как вы освоите статистику, Python и работу с данными, можно будет переходить к машинному обучению. На этом этапе важно понять не только как запускать готовые модели, но и в каких задачах они применяются, какие у них ограничения и как оценивать качество результатов.
Начните с базовых алгоритмов: линейной и логистической регрессии, деревьев решений, случайного леса и градиентного бустинга. Эти методы лежат в основе многих практических задач — от прогнозирования спроса до оценки рисков и рекомендательных систем.
Параллельно осваивайте библиотеку Scikit-learn — один из основных инструментов для машинного обучения на Python. С её помощью можно подготовить данные, обучить модель и проверить её качество на реальных датасетах.
Где учить: для старта подойдёт Open Machine Learning Course от сообщества Open Data Science (ODS). Курс помогает разобраться в ключевых алгоритмах машинного обучения и показывает, как применять их на практике.
Шаг 5: откликайтесь на стажировки
После изучения базы начинайте откликаться на стажировки и позиции для начинающих специалистов. Не ждите момента, когда будете знать всё: требования в вакансиях часто превышают реальные ожидания работодателей от джуниоров.
Если получили отказ — проанализируйте обратную связь, определите пробелы в знаниях и продолжайте учиться. Параллельно наполняйте портфолио, участвуйте в соревнованиях по анализу данных и решайте практические задачи — это поможет выделиться среди других кандидатов.
Стажировки и программы для начинающих регулярно открывают крупные IT-компании, в том числе «Яндекс», VK, Ozon, «Т-Банк» и «Авито».

Что дальше
После освоения базы важно продолжать учиться, следить за новыми инструментами и решать практические задачи. В этом помогут профессиональные сообщества и специализированные платформы.
Open Data Science (ODS) — крупнейшее русскоязычное сообщество специалистов по data science, машинному обучению и анализу данных. Здесь публикуют материалы для обучения, обсуждают технические вопросы, делятся вакансиями и анонсами мероприятий.
Kaggle — международная платформа для специалистов по данным. Здесь можно участвовать в соревнованиях по машинному обучению, работать с реальными датасетами, изучать чужие решения и собирать портфолио проектов.
Towards Data Science — одно из самых популярных изданий о data science. Авторы публикуют практические руководства, разборы алгоритмов, обзоры библиотек и кейсы из индустрии.
Плюсы и минусы профессии
Со стороны профессия data scientist выглядит привлекательно: интересные задачи и высокие зарплаты. На практике всё сложнее: у профессии есть как заметные преимущества, так и свои ограничения.
Преимущества
Высокий доход. Зарплаты в data science держатся выше средних по IT-рынку. Связано это с тем, что от работы специалиста напрямую зависит прибыль бизнеса: удержанные клиенты, точные прогнозы спроса, заблокированные мошеннические переводы и так далее.
Интеллектуальные задачи. Работа напоминает научное исследование: специалист выдвигает гипотезу, проверяет её на данных, ошибается, придумывает новую — и повторяет цикл заново. Монотонности в самих задачах мало: каждая чем-то отличается от предыдущей, и решать их приходится головой, а не по шаблону.
Востребованность. Данные собирает любой крупный бизнес, поэтому дата-сайентисты нужны почти везде — от финтеха и медицины до тяжёлой промышленности. Это даёт свободу выбора: можно уйти в ту сферу, которая ближе, и не бояться остаться без работы при смене отрасли.
Недостатки
Высокий порог входа. Одного умения программировать для старта недостаточно: нужно хорошо понимать математику, статистику и теорию вероятностей. Из-за этого освоить профессию с нуля сложнее и дольше, чем, например, базовую веб-разработку.
Много рутины. Вопреки ожиданиям, обучение нейросетей занимает меньшую часть времени. Большая часть работы — это скучная, но обязательная подготовка данных: выгрузка, очистка, заполнение пропусков, исправление аномалий и так далее.
Постоянное обучение. Технологии в сфере меняются быстро: появляются новые модели, библиотеки и подходы, а вчерашние решения устаревают. Знать всё невозможно, поэтому учиться придётся непрерывно.
Коротко о главном
Data science — одно из самых перспективных направлений в IT, но и одно из самых требовательных. Если коротко:
- Data scientist превращает данные в решения. Он анализирует большие объёмы информации и обучает предсказательные модели, которые помогают бизнесу действовать на опережение: удерживать клиентов, прогнозировать спрос, отсекать мошеннические операции и так далее.
- Главное отличие от дата-аналитика — взгляд в будущее. Аналитик чаще изучает прошлое и собирает дашборды («что уже произошло»), а дата-сайентист с помощью машинного обучения прогнозирует, что произойдёт дальше.
- Базовый стек одинаков почти для всех. Это Python с библиотеками вроде Pandas и Scikit-learn, SQL для работы с базами данных и математическая статистика, без которой алгоритмы остаются «чёрным ящиком».
- Зарплаты — одни из самых высоких в IT. Junior-специалисты в России получают около 136 000 рублей, middle — порядка 248 000 рублей, senior — около 391 000 рублей и выше. На международном рынке цифры заметно больше.
Больше интересного про код — в нашем телеграм-канале. Подписывайтесь!
Курс с помощью в трудоустройстве

Профессия Data scientist + ИИ
- Реальные задачи от «СберАвтоподписки» и «СберМаркета»
- 8 сильных проектов в портфолио
- Спикеры из VK, ВТБ, «Сбера», Wildberries





