Основы PyTorch для Python-разработчика
Изучаем фреймворк и создаём простого голосового помощника.


В этой статье мы рассмотрим фреймворк PyTorch для машинного обучения. Torch — это научная вычислительная среда с поддержкой алгоритмов машинного обучения, которая ориентирована на использование графических процессоров (GPU) для ускорения вычислений. Мы начнём с базовой теории, а затем перейдём к практике: создадим голосового ассистента, который сможет распознавать речь и предоставлять актуальную информацию о погоде.
Хотя мы не будем подробно разбирать все возможности PyTorch, материал рассчитан не на полных новичков. Для понимания статьи вам нужно знать базовый синтаксис Python, уметь устанавливать библиотеки и запускать код.
Содержание
- Кому и для чего нужен PyTorch
- Как устроен PyTorch
- Создаём голосового ассистента на Python с помощью PyTorch
Кому и для чего нужен PyTorch
PyTorch — это фреймворк с открытым исходным кодом для создания и обучения нейронных сетей на Python. Его часто используют исследователи, специалисты по данным и разработчики ML-систем. Например, команда OpenAI использует PyTorch для разработки новых архитектур нейросетей, а инженеры Uber и Netflix — для создания своих рекомендательных систем.
Одно из главных преимуществ PyTorch в том, что он позволяет быстро создавать модели машинного обучения разной сложности для всевозможных задач. Для этого фреймворк включает библиотеку готовых функциональных блоков, предобученные модели и оптимизированные алгоритмы обучения.
Например, вы можете использовать модуль torchvision для распознавания изображений или библиотеку transformers для обработки текста. Такой подход значительно сокращает время разработки и избавляет от необходимости писать код с нуля. То есть вы можете сосредоточиться на задаче и не отвлекаться на настройку базовой инфраструктуры модели.
Если вы новичок в машинном обучении, то PyTorch можно представить как конструктор LEGO для создания моделей. В нём есть базовые «кубики» и готовые модули, которые можно легко комбинировать по инструкции или создавать собственные архитектуры. Кроме того, PyTorch позволяет менять «схему сборки» прямо во время работы: если определённая часть сети работает неэффективно, её можно модифицировать без перестройки всей модели.
А если вы уже работали с библиотекой NumPy, то PyTorch покажется вам во многом знакомым: в нём тоже можно выполнять привычные операции с данными и использовать похожий синтаксис. Например, операция вычисления среднего значения tensor.mean() в PyTorch по синтаксису и функциональности полностью аналогична array.mean() в NumPy.
Главное отличие в том, что PyTorch выполняет вычисления не только на процессоре (CPU), как NumPy, но и на графическом ускорителе (GPU). А это означает, что по сравнению с вычислениями только на CPU вы можете ускорить работу в 10–50 раз, особенно если речь идёт о тяжёлых задачах — например, при обработке видео, работе с большими объёмами данных и обучении моделей.
Читайте также:
Как устроен PyTorch
Фреймворк PyTorch основан на нескольких ключевых компонентах — тензорах, вычислительных графах и механизме автоматического дифференцирования. Эти компоненты работают в связке, и их можно представить как фабрику: тензоры — это сырьё (данные), вычислительный граф — чертёж и конвейер обработки, а автоматическое дифференцирование — система контроля качества, которая определяет, что нужно изменить для улучшения результата.
Тензоры — это многомерные массивы данных, которые оптимизированы для параллельных вычислений на GPU и могут иметь любое количество измерений. Например, одномерный тензор — это вектор [1, 2, 3], двухмерный — матрица [[1, 2], [3, 4]], а трёхмерный — «куб» данных [[[1, 2], [3, 4]], [[5, 6], [7, 8]]]. Для удобства представляйте тензор как таблицу чисел, которую можно расширять в длину, ширину и глубину.
Вычислительные графы — архитектурная схема, которая отображает последовательность и взаимосвязь операций над данными. В такой схеме узлы представляют различные математические операции, а рёбра — потоки данных-тензоров. Этот подход позволяет наглядно проследить, как данные трансформируются от входного слоя нейросети до финального результата.
Например, выражение c = a + b в PyTorch можно представить как небольшой граф: два входа с данными (a и b) подключаются к узлу операции «сложение», а результат (c) идёт на выход. Такая схема позволяет фреймворку отслеживать порядок и взаимосвязь всех операций. Поэтому, если вы измените входные данные или захотите пересчитать результат, PyTorch просто повторит те же шаги и выдаст обновлённый ответ.
Механизм автоматического дифференцирования — это встроенная в PyTorch система, которая автоматически вычисляет, как меняются выходные значения модели при изменении её параметров. Эти изменения называют градиентами. Благодаря этому механизму нейросеть сама определяет, какие параметры и как нужно скорректировать для улучшения результата — программисту при этом не нужно вручную считать сложные производные.
К примеру, если нейросеть для распознавания изображений перепутала кошку с собакой, этот механизм рассчитает веса нейронов и то, насколько нужно их изменить, чтобы в следующий раз повысить точность распознавания.
В следующем разделе мы будем создавать голосового ассистента. В этом проекте тензоры, вычислительные графы и механизм автоматического дифференцирования будут работать примерно в таком порядке:
- Преобразование звука в данные — аудиосигнал конвертируется в спектрограммы и последовательности численных значений (тензоров), которые отражают частотные и временные характеристики речи.
- Обработка в вычислительном графе — тензоры проходят через цепочку операций: сначала из них извлекаются звуковые признаки, затем происходит распознавание слов, а в конце формируется ответ.
- Анализ ошибки — если модель распознала речь неправильно, PyTorch вычисляет, какие параметры (веса) необходимо скорректировать.
- Обновление модели — PyTorch корректирует параметры модели, чтобы повысить точность распознавания при следующих попытках.
Благодаря такому взаимодействию компонентов модель может постепенно обучаться и точнее распознавать речь. Переходим к сборке нашего ассистента.

Читайте также:
Создаём голосового помощника на Python и PyTorch
В этом разделе мы поработаем с API, подключим внешние библиотеки и напишем несколько функций для запуска голосового ассистента. Это будет простая программа, но вы можете доработать её и добавить функции, которые сочтёте полезными. Например, в нашей версии ассистент не умеет включать музыку, однако вы можете это исправить или реализовать другую команду.
Подготовка
Перед написанием кода перейдите на сайт openweathermap.org, где собраны данные о погоде по всему миру. Мы будем использовать его API, чтобы голосовой помощник мог отвечать на вопрос «Какая сейчас погода?» в заданном городе. При желании вы можете выбрать другой похожий ресурс.
После регистрации на сайте зайдите в личный кабинет, найдите раздел «My API Keys» и скопируйте сгенерированный ключ — это строка из букв и цифр:
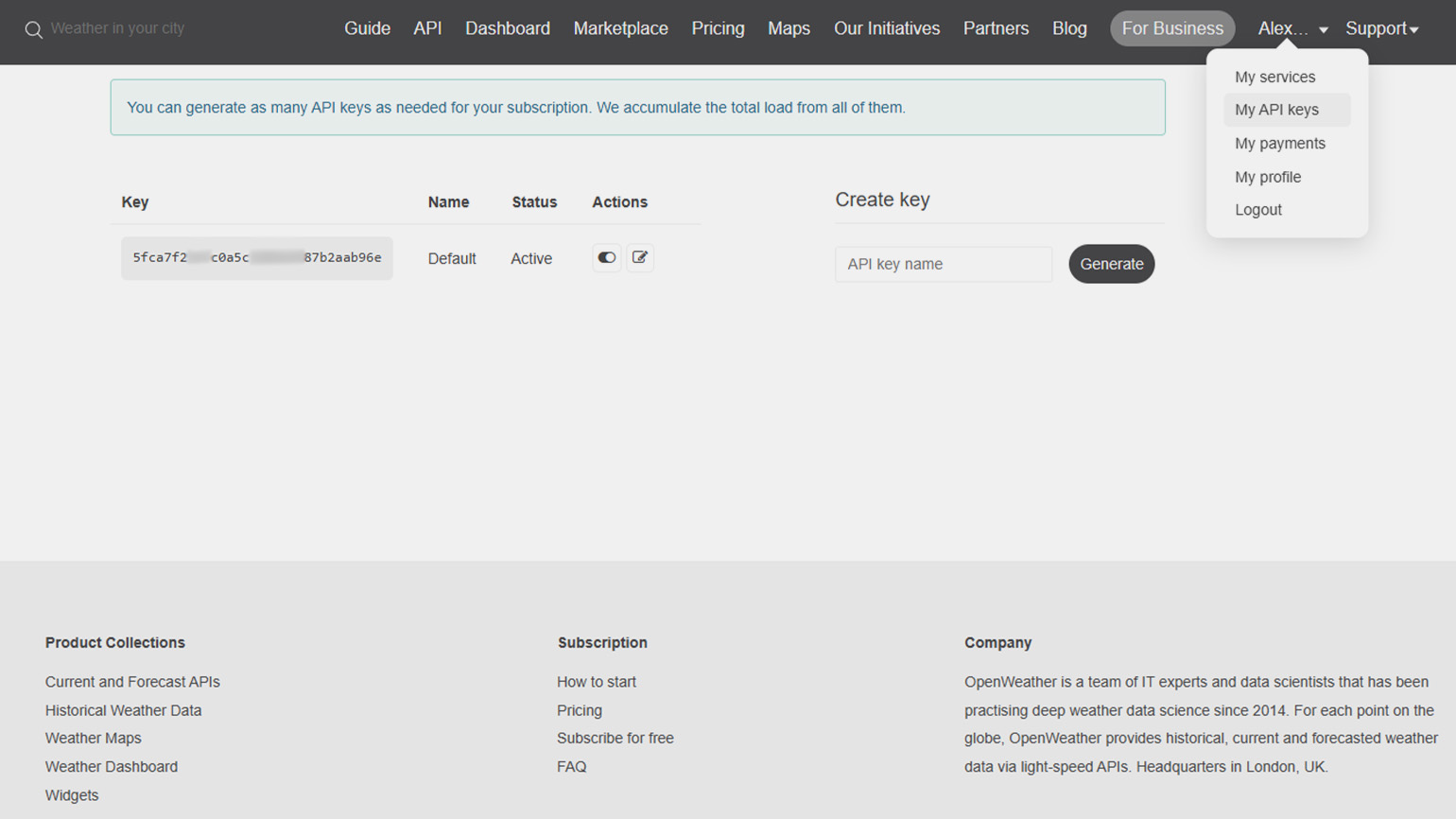
Скриншот: OpenWeatherMap / Skillbox Media
Полученный API-ключ необходимо сохранить в переменной окружения WEATHER_API_KEY. Переменную окружения можно создать временно для текущей сессии терминала или постоянно. Для учебного проекта достаточно временного варианта, поэтому введите в Windows PowerShell две команды:
# Устанавливаем переменную окружения только для текущей сессии
$env:WEATHER_API_KEY="ВАШ_КЛЮЧ"
# Проверяем, что ключ установлен
echo $env:WEATHER_API_KEY
# Если ключ успешно сохранён, в ответ отобразится введённое значение — ваш API-ключПо-хорошему, на подготовительном этапе нам следовало бы обучить модель с нуля, чтобы она адаптировалась именно под наши задачи. Однако этот процесс требует времени, значительных вычислительных ресурсов и крупных наборов размеченных аудиозаписей. Чтобы упростить задачу, мы используем готовую модель распознавания речи Wav2Vec 2.0 в русской версии — jonatasgrosman/wav2vec2-large-xlsr-53-russian с платформы Hugging Face.
Устанавливаем зависимости и формируем проект
Для работы нам понадобится несколько внешних библиотек, которые можно установить одной командой:
pip install torch torchaudio transformers pyaudio pyttsx3 requests numpyКратко разбираемся, что и для чего нужно:
- PyTorch — для запуска и обработки нейросети,
- Torchaudio — для работы со звуковыми файлами (ресемплинга),
- Transformers — для загрузки предобученной модели Wav2Vec 2.0,
- PyAudio — для записи звука с микрофона,
- pyttsx3 — для синтеза речи (озвучивания),
- Requests — для выполнения HTTP-запросов к погодному API,
- NumPy — для работы с аудиоданными при чтении WAV.
Для работы будем использовать редактор VS Code, но вы можете выбрать любой другой. Создайте папку для проекта и как-то её назовите — например, voice_assistant. Внутри этой папки создайте файл с расширением .py — у нас это будет assistant.py. Дополнительно вы можете создать виртуальное окружение, чтобы изолировать зависимости проекта.
Если что-то не работает, убедитесь, что у вас на компьютере установлена актуальная версия Python (3.8 или выше). Проверить это можно командой:
python --version
Пишем код и запускаем голосового помощника
Сначала мы импортируем библиотеки для работы со звуком, нейросетью и выполнения интернет-запросов. После этого загрузим модель Wav2Vec 2.0, которая сможет преобразовать записанное с микрофона аудио в текст.
Дальше мы создадим несколько функций: одна будет записывать звук, вторая — преобразовывать его в текст, третья — получать прогноз погоды, а четвёртая — озвучивать ответ. Также у нас будет отдельная функция для обработки команд: она анализирует распознанный текст и определяет, что сделать — ответить приветствием, сообщить погоду или сообщить, что запрос не понят.
Вся логика работает в бесконечном цикле: после запуска ассистент ждёт, когда вы нажмёте Enter, затем записывает произнесённую фразу, преобразует её в текст, анализирует команду, озвучивает ответ и прописывает его текстом.
import os
import wave
import requests
import numpy as np
import torch
import torchaudio
import pyaudio
import pyttsx3
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
# Название нашей модели и настройки
MODEL_NAME = "jonatasgrosman/wav2vec2-large-xlsr-53-russian"
current_location = "Москва" # Город по умолчанию
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Загружаем процессор и модель распознавания речи
processor = Wav2Vec2Processor.from_pretrained(MODEL_NAME)
model = Wav2Vec2ForCTC.from_pretrained(MODEL_NAME).to(DEVICE)
model.eval()
# Добавляем запись аудио с микрофона в файл
def record_audio(filename: str, duration: int = 5, sample_rate: int = 16000) -> None:
p = pyaudio.PyAudio()
stream = p.open(format=pyaudio.paInt16, channels=1, rate=sample_rate, input=True, frames_per_buffer=1024)
print("Запись началась...")
frames = [stream.read(1024) for _ in range(int(sample_rate / 1024 * duration))]
print("Запись завершена.")
stream.stop_stream()
stream.close()
p.terminate()
# Сохраняем аудиоданные в WAV
with wave.open(filename, "wb") as wf:
wf.setnchannels(1)
wf.setsampwidth(p.get_sample_size(pyaudio.paInt16))
wf.setframerate(sample_rate)
wf.writeframes(b"".join(frames))
# Настраиваем распознавание речи из WAV-файла
def transcribe_audio(filename: str) -> str:
try:
with wave.open(filename, "rb") as wf:
n_channels = wf.getnchannels()
sampwidth = wf.getsampwidth()
sr = wf.getframerate()
n_frames = wf.getnframes()
raw = wf.readframes(n_frames)
except (wave.Error, FileNotFoundError):
return ""
if n_channels != 1 or sampwidth != 2:
return ""
# Преобразуем в float32 [-1, 1]
audio = np.frombuffer(raw, dtype=np.int16).astype(np.float32) / 32768.0
# Проводим ресемплинг до 16 кГц, если нужно
if sr != 16000:
tensor = torch.from_numpy(audio).unsqueeze(0)
tensor = torchaudio.functional.resample(tensor, orig_freq=sr, new_freq=16000)
audio = tensor.squeeze(0).numpy()
sr = 16000
# Запускаем модель для получения текста
inputs = processor(audio, sampling_rate=sr, return_tensors="pt", padding=True)
input_values = inputs.input_values.to(DEVICE)
attention_mask = inputs.attention_mask.to(DEVICE) if "attention_mask" in inputs else None
with torch.no_grad():
logits = model(input_values, attention_mask=attention_mask).logits
ids = torch.argmax(logits, dim=-1)
return processor.batch_decode(ids)[0].strip()
# Получаем прогноз погоды по API
def get_weather_text(city: str) -> str:
api_key = os.environ.get("WEATHER_API_KEY")
if not api_key:
return "API-ключ не найден. Установите переменную окружения WEATHER_API_KEY."
url = "https://api.openweathermap.org/data/2.5/weather"
params = {"q": city, "appid": api_key, "lang": "ru", "units": "metric"}
try:
r = requests.get(url, params=params, timeout=10)
data = r.json()
if data.get("cod") == 200:
desc = data["weather"][0]["description"]
temp = data["main"]["temp"]
return f"Сейчас в {city} {desc}, температура {temp}°C."
msg = data.get("message") or "Не удалось получить данные."
return f"Не удалось найти погоду для {city}. {msg}"
except requests.RequestException:
return "Не удалось получить данные о погоде."
# Добавляем синтез речи (озвучку)
def speak(text: str) -> None:
engine = pyttsx3.init()
engine.say(text)
engine.runAndWait()
# Настраиваем обработку пользовательских команд
def process_command(command: str) -> str:
global current_location
cmd = command.lower().strip()
if not cmd:
return "Не расслышал команду. Повторите, пожалуйста."
if "установить местоположение" in cmd:
city = cmd.split("установить местоположение", 1)[-1].strip().title()
if city:
current_location = city
return f"Местоположение установлено на {city}."
return "Не понял город. Скажите: 'установить местоположение <город>'."
if "какая погода" in cmd or "погода" in cmd:
return get_weather_text(current_location)
if "привет" in cmd:
return "Привет!"
if "включи музыку" in cmd:
return "Включаю музыку. (Демо.)"
return "Извините, я не понял команду."
# Формируем основной цикл работы ассистента
def main():
speak(f"Голосовой помощник запущен. Текущее местоположение: {current_location}.")
print("Нажмите Enter, чтобы начать запись...")
while True:
input() # ждём нажатия Enter
record_audio("command.wav") # записываем речь
text = transcribe_audio("command.wav") # распознаём
print("Вы сказали:", text if text else "(пусто)")
answer = process_command(text) # получаем ответ
print("Ответ:", answer)
speak(answer) # озвучиваем ответ
if __name__ == "__main__":
main()Чтобы запустить голосового помощника, откройте терминал внутри редактора и выполните команду с указанием имени файла:
python assistant.pyПодождите около 20 секунд, пока ассистент загрузит модель и поприветствует вас. После этого нажмите Enter и попробуйте с ним пообщаться. Иногда при запросе погоды ассистент может не обнаружить API-ключ. В таком случае убедитесь, что терминал открыт и сессия всё ещё активна. Попробуйте перезапустить редактор. Если это не поможет, введите ключ прямо в терминале редактора и затем снова запустите голосового ассистента.
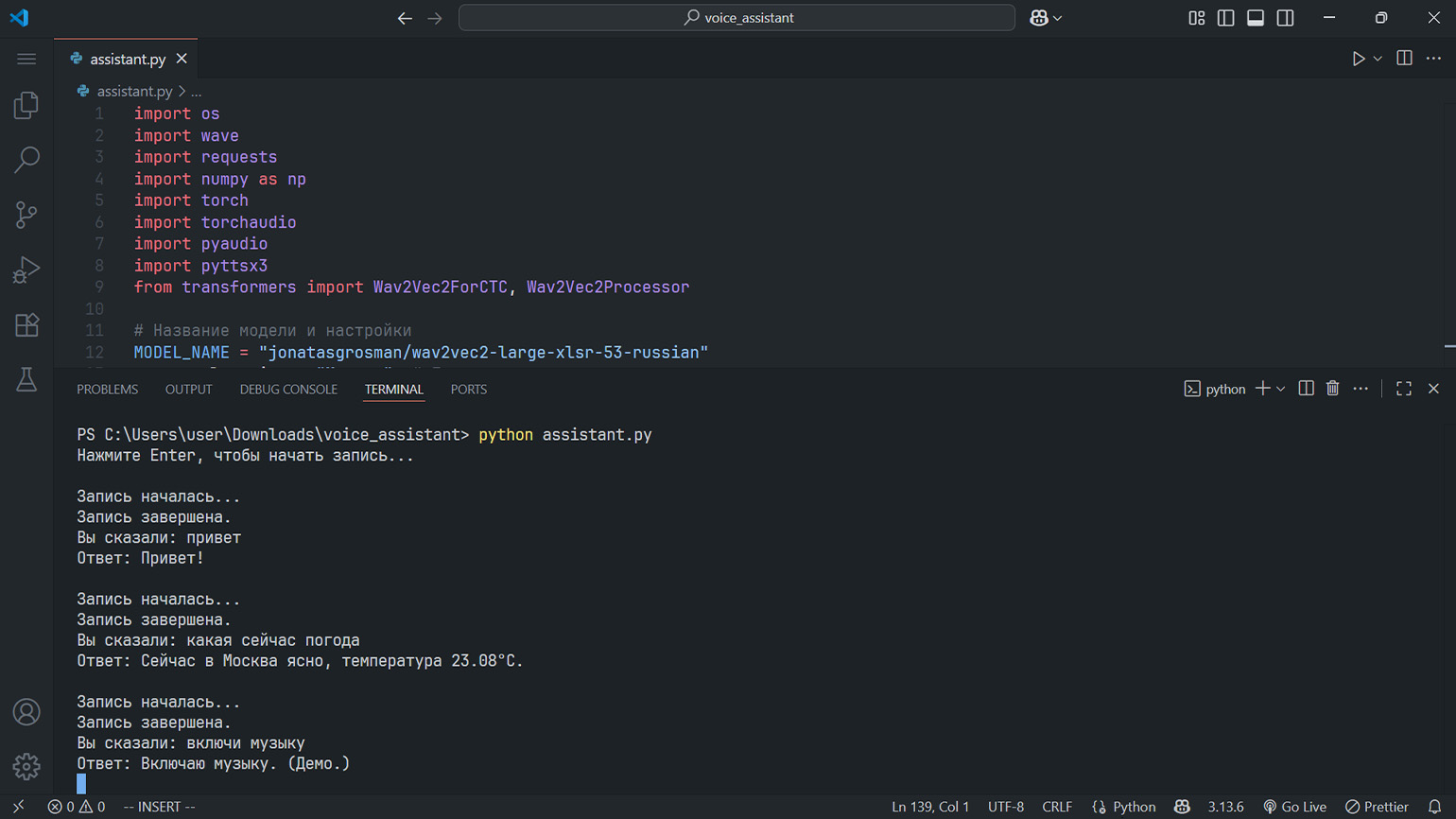
Скриншот: Visual Studio Code / Skillbox Media
Больше интересного про код — в нашем телеграм-канале. Подписывайтесь!









