Основы анализа данных для начинающих
Данные помогают управлять нашим вниманием, наращивать продажи, делать прогнозы и совершать научные открытия. И это лишь часть их суперсилы.

Каждый из нас постоянно производит данные: сообщения, посты, фото, видео, температура, пульс, уровень сахара. Эти данные важны для бизнеса, так как помогают компаниям лучше понимать клиентов и предоставлять релевантные услуги. Например, онлайн-кинотеатры используют информацию о ваших предпочтениях, чтобы рекомендовать подходящий контент.
Однако данные сами по себе бесполезны без обработки и анализа. Именно об анализе данных мы и расскажем в этой статье. Вы узнаете:
Что такое анализ данных и зачем он нужен
Анализ данных — это процесс обработки и интерпретации данных для извлечения значимой информации. Чаще всего он применяется к большим объёмам информации, которые невозможно обработать вручную.
Анализ данных используется в различных областях. Вот несколько примеров:
- В бизнесе анализ данных помогает понять поведение клиентов и оптимизировать услуги. Например, розничные сети изучают покупки для создания персонализированных предложений и оптимизации запасов.
- В здравоохранении анализ данных улучшает диагностику и позволяет разрабатывать персонализированные методы лечения. Медицинские учреждения используют данные о пациентах, чтобы предсказать риск хронических заболеваний на основе истории и образа жизни. Это помогает вовремя назначать профилактику и разрабатывать индивидуальные планы лечения.
- В науке анализ данных помогает обнаруживать новые закономерности и инновации. Например, анализ больших данных позволяет выявлять сигналы, указывающие на планеты за пределами Солнечной системы.
Анализ данных помогает принимать обоснованные решения, улучшать процессы и достигать целей, предоставляя ценные инсайты в любой сфере.
Читайте также:
Основные методы анализа данных
Анализ данных можно проводить двумя основными методами:
- Статистические методы — основаны на теории вероятностей и статистике, помогают выявлять закономерности в небольших наборах данных.
- Машинное обучение — использует алгоритмы и модели, которые обучаются на больших объёмах данных, улучшая точность и делая предсказания на основе сложных паттернов.
В этом разделе мы обсудим основные методы анализа данных: регрессию, классификацию и кластеризацию. Мы рассмотрим их применение в различных сценариях и использование в машинном обучении для решения реальных задач.

Регрессия
Регрессия — метод предсказания значения одной переменной на основе другой. Он помогает моделировать зависимости между переменными, прогнозировать результаты и выявлять закономерности.
Линейная регрессия — простой метод, предполагающий линейную связь между независимой и зависимой переменной. Например, её можно использовать для предсказания стоимости дома на основе площади. Имея данные о площади и цене нескольких домов, можно найти наиболее выгодное предложение на рынке недвижимости: дом с большой площадью по относительно низкой цене в нужном районе.
Кроме линейной регрессии существуют и другие типы регрессии:
- Множественная регрессия: расширяет линейную регрессию, добавляя несколько независимых переменных. Например, стоимость дома можно предсказать не только по площади, но и по количеству комнат, году постройки, расположению и другим параметрам.
- Полиномиальная регрессия: применяется, когда связь между переменными нелинейная. Например, стоимость дома может сначала увеличиваться пропорционально площади, но затем рост цен может замедлиться. Полиномиальная регрессия точно отражает такие нелинейные зависимости.
Регрессия применяется в оценке недвижимости, финансовых прогнозах и анализе временных рядов. Она помогает строить модели и делать предсказания, а также позволяет использовать более сложные методы, такие как регуляризация и машины опорных векторов, для повышения точности анализа.
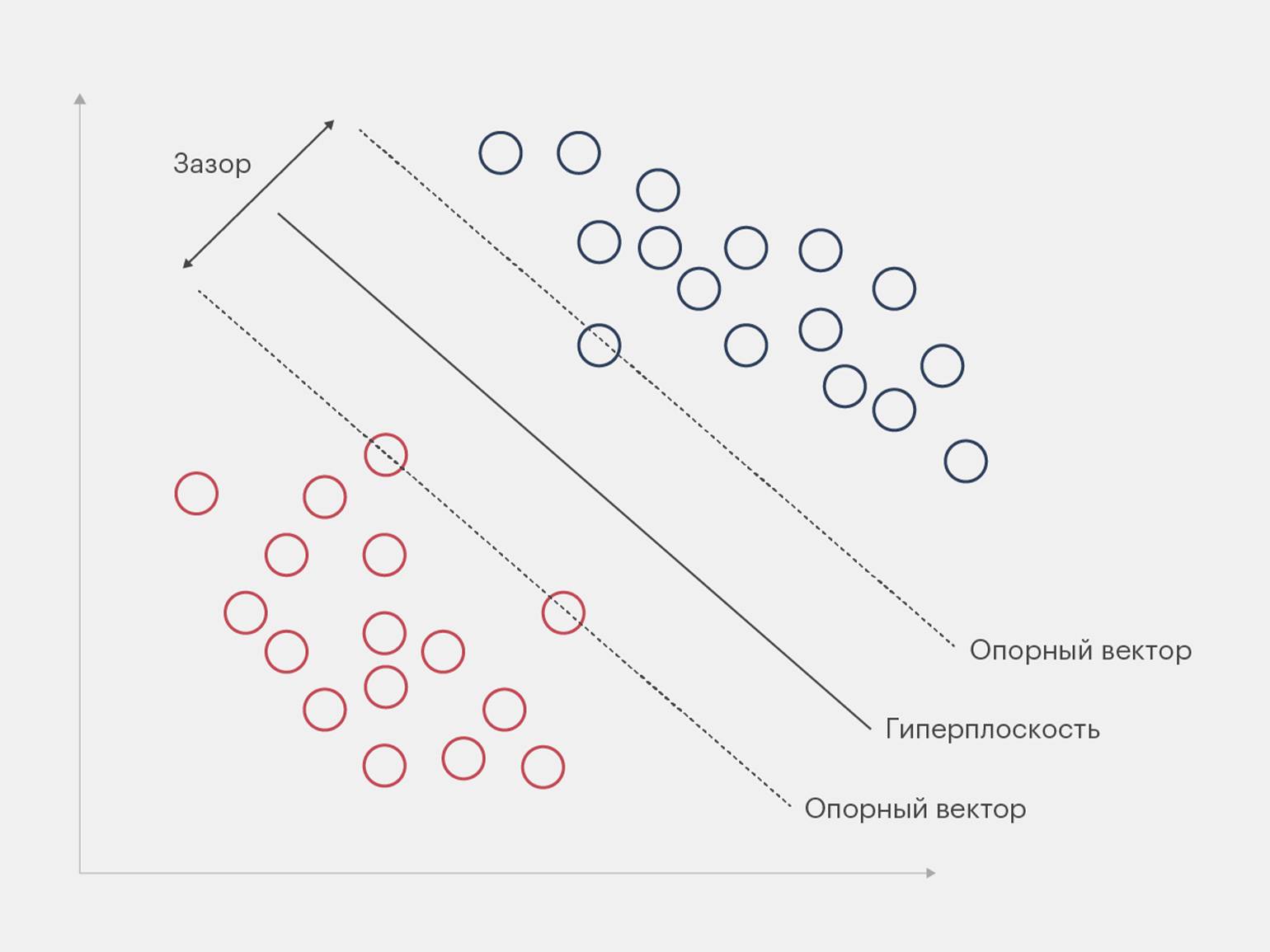
Инфографика: Майя Мальгина для Skillbox Media
Классификация
Классификация — метод анализа данных, предназначенный для определения категории, к которой принадлежит объект. Он помогает разделять объекты на заранее определённые группы или классы, что полезно для отнесения данных к одной из нескольких категорий на основе их характеристик.
Среди популярных алгоритмов классификации выделяются логистическая регрессия, деревья решений и методы на основе нейронных сетей:
- Логистическая регрессия: используется для бинарной классификации и оценки вероятности принадлежности объекта к категории. Например, она может предсказать, является ли электронное письмо спамом, основываясь на содержащихся в нём словах.
- Деревья решений: создают модели в виде деревьев, где каждый узел представляет проверку на характеристику, а листья — результаты классификации. Например, дерево решений может определить, одобрят ли заявку на кредит, задавая вопросы о доходе, кредитной истории и другой информации.
- Методы на основе нейронных сетей: включают сложные модели, которые автоматически извлекают признаки из данных и адаптируются к сложным зависимостям. Например, нейронные сети могут распознавать лица на фотографиях, обучаясь различать и идентифицировать лица по множеству изображений.
Алгоритмы классификации важны для автоматизации процессов, повышения точности предсказаний и извлечения значимых инсайтов из данных.
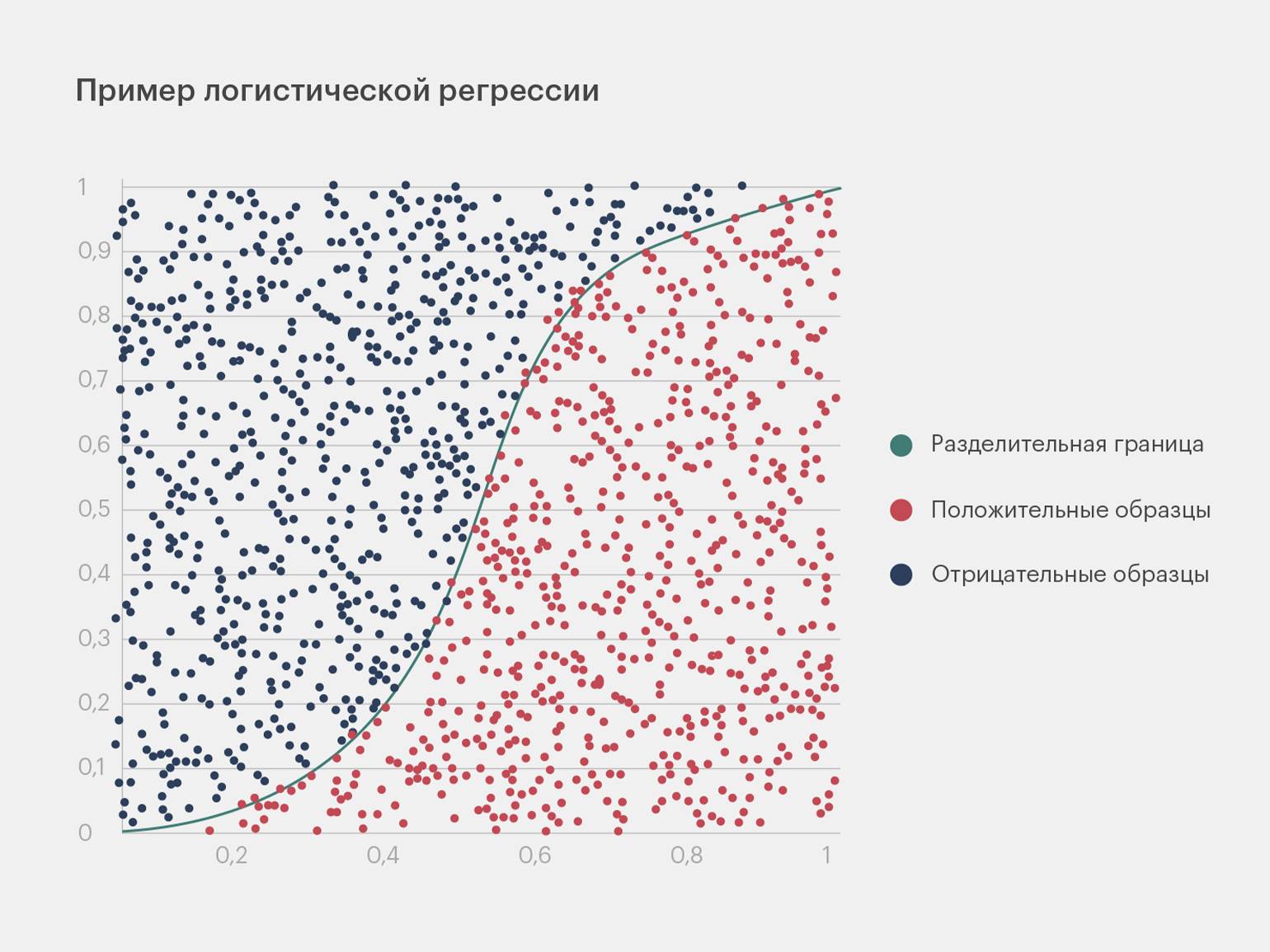
Инфографика: Майя Мальгина для Skillbox Media
Кластеризация
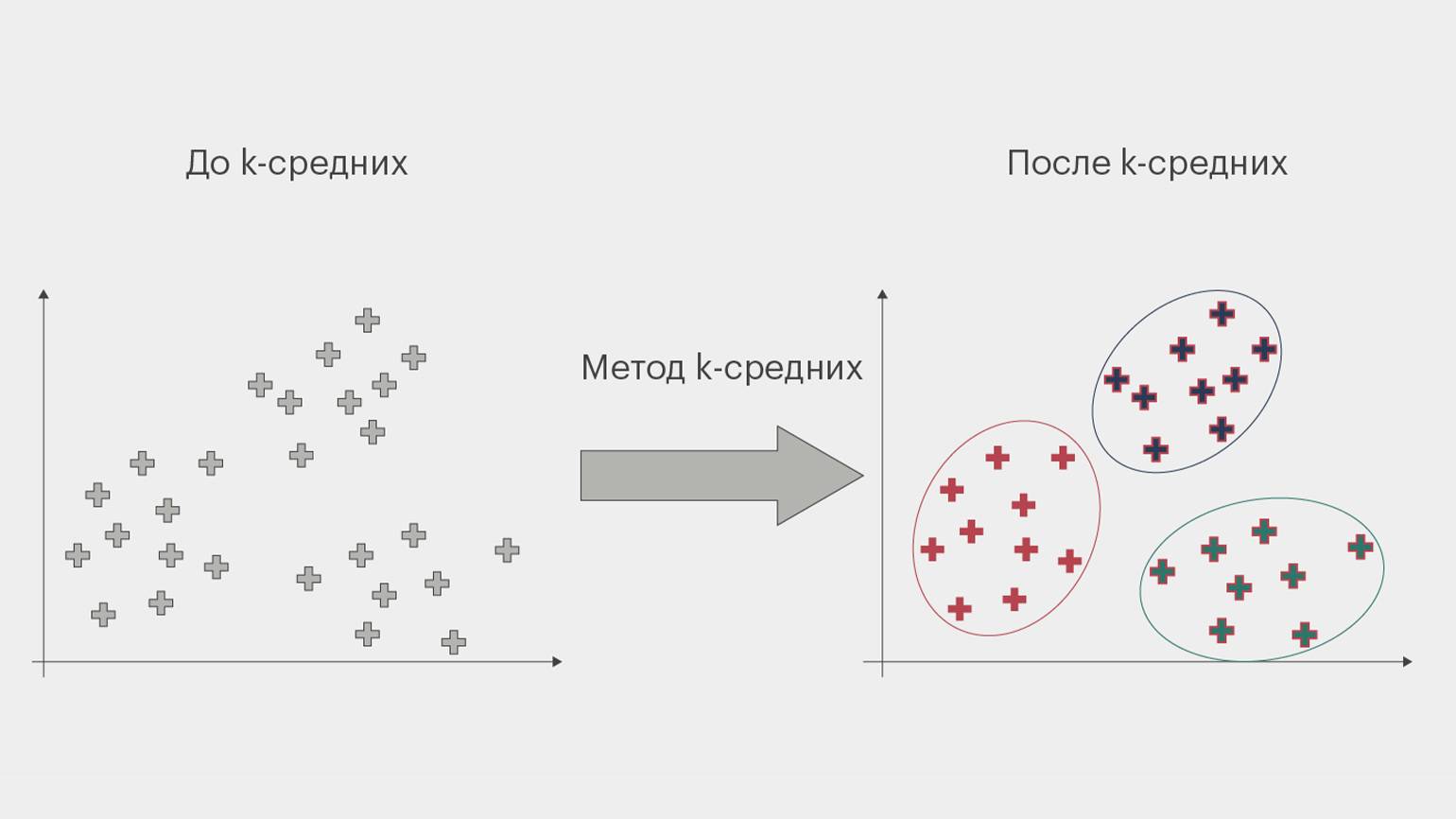
Кластеризация — метод анализа данных, группирующий объекты по сходству. Он делит данные на несколько групп (кластеров), где объекты внутри одного кластера более схожи между собой, чем с объектами из других кластеров.
Один из популярных алгоритмов кластеризации — k-средних (k-means). Он делит данные на k кластеров, где k задаётся заранее. Алгоритм работает в несколько этапов:
- Инициализация: выбираются начальные центры кластеров (центроиды). Например, в интернет-магазине одежды начальные центры могут быть выбраны случайно для трёх кластеров клиентов: массового рынка, премиум-сегмента и спортивной одежды.
- Присвоение: каждому объекту данных присваивается ближайший центр кластера. Например, девушки с похожими покупательскими привычками могут группироваться вокруг начального центра для клиентов массового рынка.
- Обновление: пересчитываются центры кластеров как среднее значение всех объектов в каждом кластере. После присвоения клиентов кластерам новые центры обновляются с учётом средних характеристик, таких как возраст, предпочтения в одежде и частота покупок. Это делает центры более точными представителями групп клиентов.
- Повторение: процесс повторяется, пока центры кластеров не стабилизируются или не достигнут оптимального состояния. Объекты будут присваиваться новым центрам до тех пор, пока изменения в позициях центров не станут незначительными.
После выполнения всех этапов алгоритма можно выделить три кластера:
- Студентки — девушки 18–24 лет, предпочитающие массовый рынок и спортивный кэжуал.
- Молодые мамы, покупающие детскую одежду для детей до четырёх лет.
- Бизнес-леди, покупающие одежду среднего и люксового сегмента в деловом стиле.
Эти кластеры можно использовать для создания персонализированных предложений и рекламных кампаний, что помогает увеличить прибыль и улучшить клиентский опыт.
Кластеризация предоставляет мощные инструменты для анализа данных, выявляя скрытые паттерны и группы в больших массивах информации. Она помогает сегментировать рынок и персонализировать услуги, что важно для создания эффективных маркетинговых стратегий.
Инфографика: Майя Мальгина для Skillbox Media

Процесс анализа данных
Процесс анализа данных включает последовательные шаги, которые преобразуют необработанные данные в полезные сведения и поддерживают принятие решений. Рассмотрим этот процесс на примере онлайн-магазина с данными о клиентах: Ф. И. О., номерами заказов, списками проданных и непроданных товаров. В исходном виде эти данные трудны для использования, но при правильном подходе они могут предоставить ценную информацию.
Постановка задачи
Для начала важно определить, какую информацию вы хотите извлечь из данных. Например, если ваша цель — увеличить прибыль, необходимо выяснить, какие товары покупатели приобретают чаще всего и какие из них приносят наибольший доход.
Допустим, магазин продаёт мелкую электронику. Вы заметили, что покупатели чаще всего приобретают наушники, зарядные устройства и чехлы для телефонов. Однако это не обязательно означает, что аксессуары более выгодны для бизнеса. Например, смартфон может стоить 20 тысяч рублей, в то время как наушники — полторы тысячи. Только анализ данных может точно показать, какая стратегия приносит больше дохода: частые продажи недорогих товаров или редкие, но дорогостоящие сделки.
Сбор данных
Для повышения прибыли важно определить факторы, влияющие на доходность бизнеса. Рассмотрим, что это может быть.
Данные о продажах:
- Перечень товаров в ассортименте.
- Количество проданных единиц каждого товара.
- Цена продажи каждого товара.
- Дата и время продажи.
- Общая сумма выручки.
Данные о затратах:
- Себестоимость товара: затраты на закупку или производство товара.
- Транспортные расходы: стоимость доставки товаров в магазин.
- Рекламные расходы: затраты на продвижение товаров.
Данные о клиентах:
- Возраст, пол и место жительства покупателей.
- Данные о предыдущих покупках.
- Частота покупок.
Данные об акциях и скидках:
- Информация о проведённых акциях и скидках.
- Период проведения и сроки акций.
- Влияние акций на объём продаж.
Данные о возвратах:
- Причины возврата товаров.
- Количество возвращённых товаров.
- Товары, которые возвращаются чаще всего.
Анализировать данные вручную сложно, поэтому для упрощения процесса используются различные инструменты:
- Системы управления заказами (например, Shopify, Magento, «1С»): автоматически фиксируют данные о каждом заказе.
- Платёжные системы: собирают информацию о платежах, включая методы оплаты и суммы.
- Регистрационные формы: собирают данные о пользователях при регистрации.
- История покупок: хранит данные о предыдущих заказах клиентов.
- Куки (cookies) и веб-аналитика (Google Analytics, «Яндекс Метрика»): отслеживает поведение пользователей на сайте.
- Инструменты для тепловых карт (Hotjar, Crazy Egg): показывают, куда пользователи кликают и как перемещаются по сайту.
Эти инструменты помогают владельцам бизнеса собирать и анализировать данные, выявлять ключевые тенденции, понимать потребности клиентов и принимать обоснованные решения для увеличения прибыли.
Хранение данных
Собранные данные нужно сохранить и организовать для дальнейшего анализа. Для этого их часто помещают в централизованное хранилище, называемое озером данных. В этом хранилище информация сохраняется в её исходном формате, независимо от источника и типа. Это могут быть фотографии товаров, отзывы клиентов, данные о транзакциях и другое.
Можно выделить два основных типа данных:
- Структурированные данные: организованы в фиксированные таблицы. Примером являются таблицы с информацией о клиентах и заказах, собранные автоматически с помощью систем управления заказами (CRM). Эти данные легко обрабатывать и анализировать с использованием реляционных баз данных и языка SQL.
- Неструктурированные данные: не имеют фиксированной структуры и могут быть представлены в различных форматах, таких как текстовые отзывы клиентов, изображения или видео. Работа с такими данными сложнее, поэтому их обычно хранят в нереляционных базах данных, таких как MongoDB. Для анализа часто применяются методы машинного обучения, включая технологии обработки естественного языка (NLP) для анализа текста и выделения ключевых слов.
Очистка данных
Собранные данные часто содержат ошибки или ненужную информацию, от которой нужно избавляться. Рассмотрим основные шаги:
- Удаление дубликатов: убедитесь, что одна и та же информация не учитывается несколько раз. Если один и тот же клиент был случайно учтён дважды, это может привести к ошибочному расчёту среднего чека или количества уникальных покупателей.
- Обработка пропущенных значений: пропуски могут вызвать искажения или ошибки в анализе. Например, отсутствие информации о цене товара может повлиять на расчёт прибыли. Пропуски можно заполнить подходящими значениями или удалить, если данных недостаточно для достоверного анализа.
- Исправление ошибок: опечатки, неправильные форматы или неверные значения могут привести к неправильной интерпретации данных. Если цена товара указана как «10000» вместо «100.00», это может исказить выводы о продажах.
- Нормализация данных: приведение данных к единому формату упрощает их анализ и сравнение. Если даты записаны в разных форматах (день/месяц/год и месяц/день/год), это может вызвать путаницу при обработке.
- Удаление ненужной информации: сосредоточьте внимание на важных и полезных данных. Например, информация о погоде в день покупки может быть нерелевантной для анализа покупательского поведения, если только она не является частью конкретного исследования.
Визуализация данных
Очищенные данные можно представить в наглядном виде для лучшего восприятия. Для этого существуют различные инструменты визуализации, каждый из которых подходит для определённых задач:
- Microsoft Excel: позволяет создавать простые визуализации для структурированных данных, например графики продаж по месяцам. Это удобный инструмент для базового анализа и создания отчётов.
- Tableau: используется для создания интерактивных графиков и дашбордов. Этот инструмент подходит для отслеживания ключевых показателей и анализа данных на регулярных встречах.
- Google Data Studio: бесплатный инструмент для создания отчётов и дашбордов. Подходит для автоматического обновления отчётов и отображения данных о конверсии с различных маркетинговых каналов. Хорош для интеграции с другими сервисами Google.
- Python с библиотеками Matplotlib, Seaborn, Plotly: подходит для кастомных визуализаций и глубокого анализа данных. Эти инструменты обеспечивают гибкость в создании нестандартных графиков и диаграмм.
Выбор типа графика зависит от цели анализа и типа данных:
- Линейный график: отображает изменения во времени, например то, как меняются продажи в течение года. Полезен для анализа трендов и сезонных колебаний.
- Столбчатая диаграмма: используется для сравнения продаж разных категорий товаров.
- Круговая диаграмма: показывает долю рынка, которую занимает каждый продукт.
- Гистограмма: помогает отображать распределения цен на товары.
- Точечная диаграмма: подходит для выявления корреляций между двумя переменными, например между ценой товара и продажами.

Читайте также:
Изучение данных
На финальном этапе необходимо извлечь полезную информацию из собранных данных. Для этого применяются несколько ключевых методов:
- Обобщение данных: позволяет рассчитать количество проданных товаров, общую выручку, средний чек и другие важные показатели.
- Группировка данных: помогает разбить общие показатели на более детализированные категории для более глубокого анализа. Это позволяет выявить изменения в продажах и выручке по различным периодам времени или категориям товаров.
- Исследование зависимостей: на этом этапе изучаются связи между различными переменными. Например, анализ влияния скидок на объём продаж помогает понять, как изменения в одной переменной (скидки) влияют на другую (объём продаж).
- Определение трендов и тенденций: помогает выявить, какие товары пользуются спросом в определённые времена года или дни недели. Это знание может быть полезным для оптимизации складских запасов и разработки эффективных рекламных стратегий.
Больше интересного про код — в нашем телеграм-канале. Подписывайтесь!






